Memory addressing modes
In our initial implementation, the CPU receives instructions as a separate input stream, this is not how things work in an actual NES.
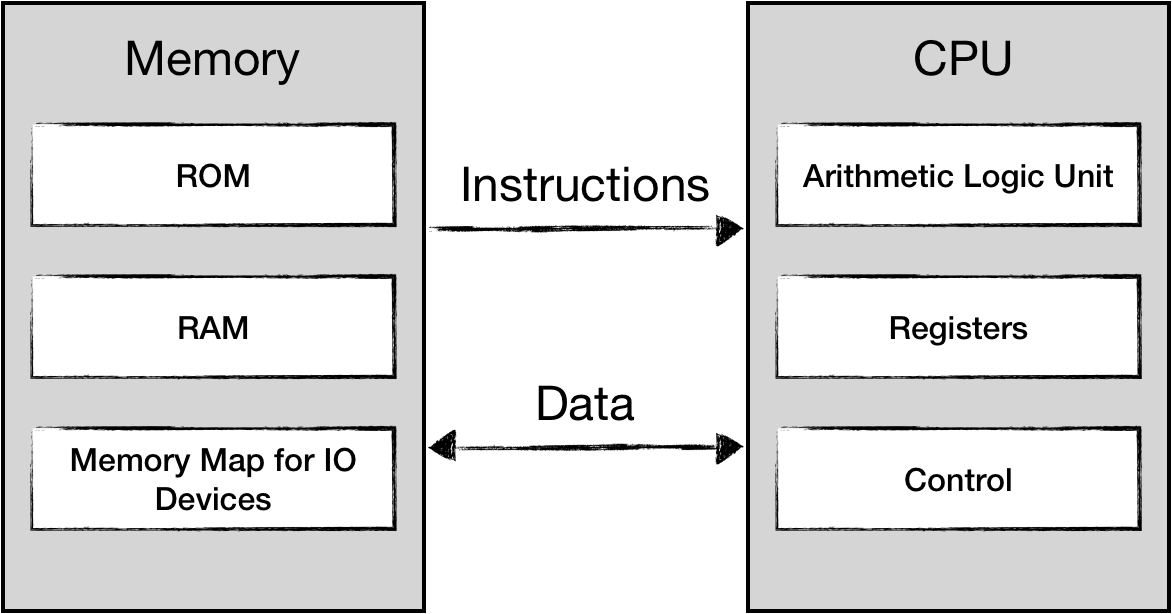
NES implements typical von Neumann architecture: both data and the instructions are stored in memory. The executed code is data from the CPU perspective, and any data can potentially be interpreted as executable code. There is no way CPU can tell the difference. The only mechanism the CPU has is a program_counter register that keeps track of a position in the instructions stream.
Let's sketch this out in our CPU code:
#![allow(unused)] fn main() { pub struct CPU { pub register_a: u8, pub register_x: u8, pub status: u8, pub program_counter: u16, memory: [u8; 0xFFFF] } impl CPU { fn mem_read(&self, addr: u16) -> u8 { self.memory[addr as usize] } fn mem_write(&mut self, addr: u16, data: u8) { self.memory[addr as usize] = data; } pub fn load_and_run(&mut self, program: Vec<u8>) { self.load(program); self.run() } pub fn load(&mut self, program: Vec<u8>) { self.memory[0x8000 .. (0x8000 + program.len())].copy_from_slice(&program[..]); self.program_counter = 0x8000; } pub fn run(&mut self) { // note: we move intialization of program_counter from here to load function loop { let opscode = self.mem_read(self.program_counter); self.program_counter += 1; match opscode { //.. } } } } }
We have just created an array for the whole 64 KiB of address space. As discussed in a future chapter, CPU has only 2 KiB of RAM, and everything else is reserved for memory mapping.
We load program code into memory, starting at 0x8000 address. We've discussed that [0x8000 .. 0xFFFF] is reserved for Program ROM, and we can assume that the instructions stream should start somewhere in this space (not necessarily at 0x8000).
NES platform has a special mechanism to mark where the CPU should start the execution. Upon inserting a new cartridge, the CPU receives a special signal called "Reset interrupt" that instructs CPU to:
- reset the state (registers and flags)
- set program_counter to the 16-bit address that is stored at 0xFFFC
Before implementing that, I should briefly mention that NES CPU can address 65536 memory cells. It takes 2 bytes to store an address. NES CPU uses Little-Endian addressing rather than Big-Endian. That means that the 8 least significant bits of an address will be stored before the 8 most significant bits.
To illustrate the difference:
| Real Address | 0x8000 |
| Address packed in big-endian | 80 00 |
| Address packed in little-endian | 00 80 |
For example, the instruction to read data from memory cell 0x8000 into A register would look like:
LDA $8000 <=> ad 00 80
We can implement this behaviour using some of Rust's bit arithmetic:
#![allow(unused)] fn main() { fn mem_read_u16(&mut self, pos: u16) -> u16 { let lo = self.mem_read(pos) as u16; let hi = self.mem_read(pos + 1) as u16; (hi << 8) | (lo as u16) } fn mem_write_u16(&mut self, pos: u16, data: u16) { let hi = (data >> 8) as u8; let lo = (data & 0xff) as u8; self.mem_write(pos, lo); self.mem_write(pos + 1, hi); } }
Technically, mem_read_u16 doesn't need
&mut selfand can use immutable reference. However, later in the book, mem read requests could be routed to external "devices" (such as PPU and Joypads), where reading does indeed modify the state of the simulated device.
Or by using Rust's endian support for primitive types.
Now we can implement reset functionality properly. We will have to adjust the load and load_and_run functions:
- load method should load a program into PRG ROM space and save the reference to the code into 0xFFFC memory cell
- reset method should restore the state of all registers, and initialize program_counter by the 2-byte value stored at 0xFFFC
#![allow(unused)] fn main() { pub fn reset(&mut self) { self.register_a = 0; self.register_x = 0; self.status = 0; self.program_counter = self.mem_read_u16(0xFFFC); } pub fn load(&mut self, program: Vec<u8>) { self.memory[0x8000 .. (0x8000 + program.len())].copy_from_slice(&program[..]); self.mem_write_u16(0xFFFC, 0x8000); } pub fn load_and_run(&mut self, program: Vec<u8>) { self.load(program); self.reset(); self.run() } }
Don't forget to fix failing tests now :trollface:
Alright, that was the easy part.
Remember LDA opcodes we implemented last chapter? That single mnemonic (LDA) actually can be translated into 8 different machine instructions depending on the type of the parameter:
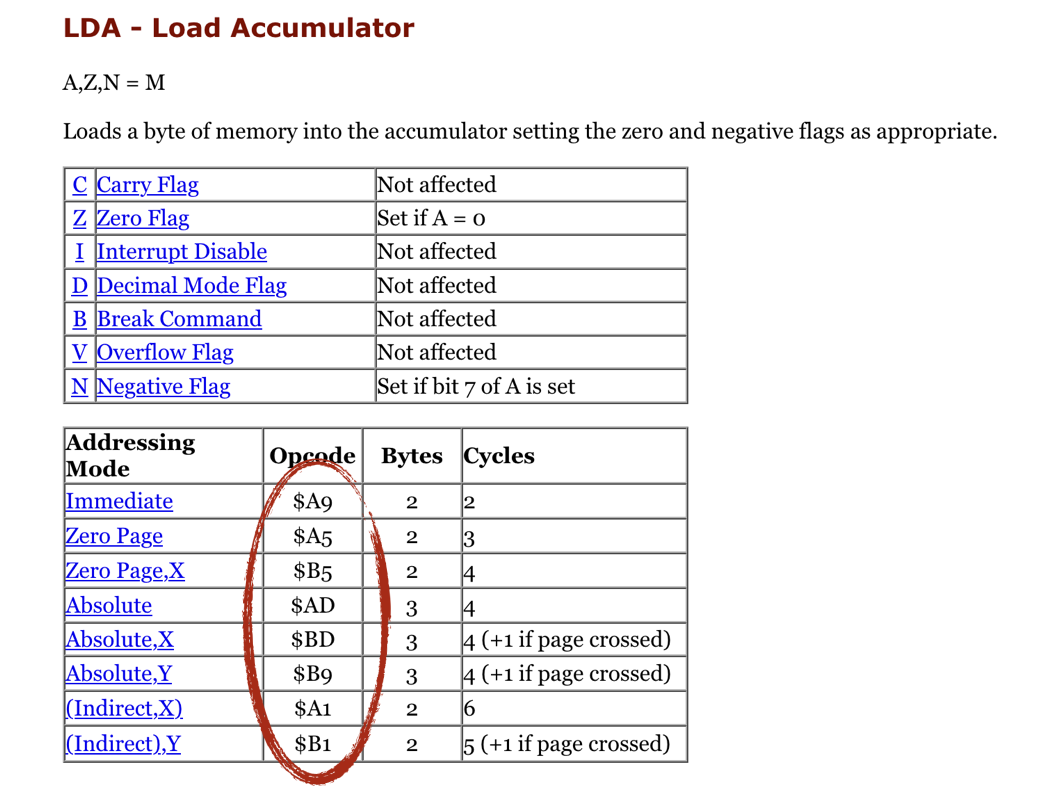
You can read about addressing modes:
In short, the addressing mode is a property of an instruction that defines how the CPU should interpret the next 1 or 2 bytes in the instruction stream.
Different addressing modes have different instruction sizes, for example:
- Zero Page version ($A5) has a size of 2 bytes, one for opcode itself, and one for a parameter. That's why zero page addressing can't reference memory above the first 255 bytes.
- Absolute version ($AD) has 3 bytes, the Address occupies 2 bytes making it possible to reference all 65536 memory cells. (NOTE: 2-byte the parameter will be packed according to little-endian rules)
There are no opcodes that occupy more than 3 bytes. CPU instruction size can be either 1, 2, or 3 bytes.
The majority of CPU instructions provide more than one addressing alternative. Ideally, we don't want to re-implement the same addressing mode logic for every CPU instruction.
Let's try to codify how the CPU should interpret different addressing modes:
#![allow(unused)] fn main() { #[derive(Debug)] #[allow(non_camel_case_types)] pub enum AddressingMode { Immediate, ZeroPage, ZeroPage_X, ZeroPage_Y, Absolute, Absolute_X, Absolute_Y, Indirect_X, Indirect_Y, NoneAddressing, } impl CPU { // ... fn get_operand_address(&self, mode: &AddressingMode) -> u16 { match mode { AddressingMode::Immediate => self.program_counter, AddressingMode::ZeroPage => self.mem_read(self.program_counter) as u16, AddressingMode::Absolute => self.mem_read_u16(self.program_counter), AddressingMode::ZeroPage_X => { let pos = self.mem_read(self.program_counter); let addr = pos.wrapping_add(self.register_x) as u16; addr } AddressingMode::ZeroPage_Y => { let pos = self.mem_read(self.program_counter); let addr = pos.wrapping_add(self.register_y) as u16; addr } AddressingMode::Absolute_X => { let base = self.mem_read_u16(self.program_counter); let addr = base.wrapping_add(self.register_x as u16); addr } AddressingMode::Absolute_Y => { let base = self.mem_read_u16(self.program_counter); let addr = base.wrapping_add(self.register_y as u16); addr } AddressingMode::Indirect_X => { let base = self.mem_read(self.program_counter); let ptr: u8 = (base as u8).wrapping_add(self.register_x); let lo = self.mem_read(ptr as u16); let hi = self.mem_read(ptr.wrapping_add(1) as u16); (hi as u16) << 8 | (lo as u16) } AddressingMode::Indirect_Y => { let base = self.mem_read(self.program_counter); let lo = self.mem_read(base as u16); let hi = self.mem_read((base as u8).wrapping_add(1) as u16); let deref_base = (hi as u16) << 8 | (lo as u16); let deref = deref_base.wrapping_add(self.register_y as u16); deref } AddressingMode::NoneAddressing => { panic!("mode {:?} is not supported", mode); } } } }
That way, we can change our initial LDA implementation.
#![allow(unused)] fn main() { fn lda(&mut self, mode: &AddressingMode) { let addr = self.get_operand_address(mode); let value = self.mem_read(addr); self.register_a = value; self.update_zero_and_negative_flags(self.register_a); } pub fn run(&mut self) { loop { let code = self.mem_read(self.program_counter); self.program_counter += 1; match code { 0xA9 => { self.lda(&AddressingMode::Immediate); self.program_counter += 1; } 0xA5 => { self.lda(&AddressingMode::ZeroPage); self.program_counter += 1; } 0xAD => { self.lda(&AddressingMode::Absolute); self.program_counter += 2; } //.... } } } }
NOTE: It's absolutely necessary to increment program_counter after each byte being read from the instructions stream.
Don't forget your tests.
#![allow(unused)] fn main() { #[test] fn test_lda_from_memory() { let mut cpu = CPU::new(); cpu.mem_write(0x10, 0x55); cpu.load_and_run(vec![0xa5, 0x10, 0x00]); assert_eq!(cpu.register_a, 0x55); } }
Using the same foundation, we can quickly implement STA instruction, which copies the value from register A to memory.
#![allow(unused)] fn main() { fn sta(&mut self, mode: &AddressingMode) { let addr = self.get_operand_address(mode); self.mem_write(addr, self.register_a); } pub fn run(&mut self) { //... match code { //.. /* STA */ 0x85 => { self.sta(AddressingMode::ZeroPage); self.program_counter += 1; } 0x95 => { self.sta(AddressingMode::ZeroPage_X); self.program_counter += 1; } //.. } } }
Before we wrap up, I'd like to mention that the current run method is somewhat iffy for a few reasons. First, the requirement to increment program_counter by 1 (or 2) after some of the operations is error-prone. If we made an error, it would be tough to spot it.
Second, wouldn't it be more readable and convenient if we could group all "LDA" operations under a single match statement?
Lastly, all we are doing is hard-coding Instructions spec into Rust code. The translation is a bit hard to compare. Keeping the code in some table form looks like a more manageable approach.
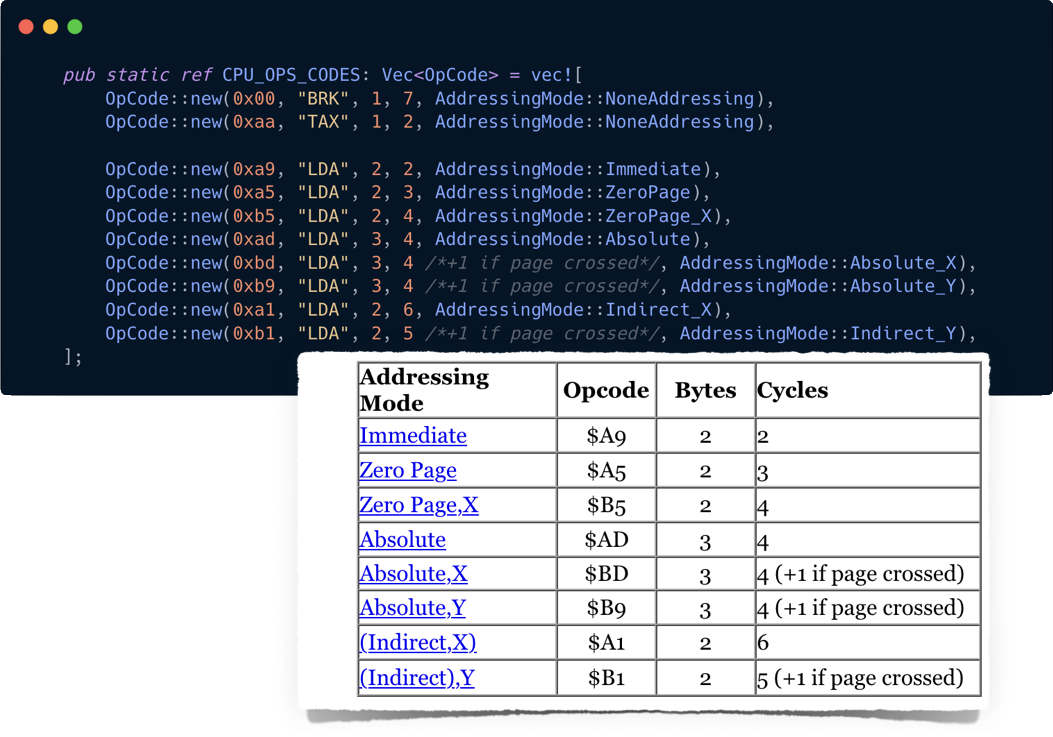
I leave it to you to figure out how to get to this point.
The full source code for this chapter: GitHub